Welcome to the AI Safety Newsletter by the Center for AI Safety. We discuss developments in AI and AI safety. No technical background required.
In this edition, we look at a new ethical framework for human-AI relationships, how the AI safety discussion has entered the political mainstream, and the Musk v. Altman trial.
Listen to the AI Safety Newsletter for free on Spotify or Apple Podcasts.
Pope Leo XIV Publishes Encyclical on AI
Last week, Pope Leo XIV published an encyclical titled Magnifica Humanitas “On Safeguarding the Human Person in the Time of Artificial Intelligence.”

The encyclical touched on concerns including unemployment and AI relationships. The publication discussed numerous potential impacts of AI on society, from job displacement and autonomous weapons to misinformation and interference in human relationships. However, the Pope did not object to the technology itself; rather, he said we can embrace technology while ensuring it is used responsibly. The encyclical warned of the potential for power concentration and called for broad participation in a discussion about the moral values that AI should be aligned with.
The encyclical did not explicitly mention extinction risks. While the publication emphasized that technology must serve humanity, some have pointed out that it does not mention artificial general intelligence, superintelligence, or the existential threat that AI could pose to humanity. These concepts appeared in Antiqua et Nova, a Church document on AI that was published in January 2025, a few months before the start of the current papacy. Others have said the encyclical “dodges” hard questions about what it will mean for machines to surpass human intelligence and criticized its seeming dismissiveness of the possibility of AI personhood.
Interactions between the Church and tech companies have drawn criticism. The Vatican invited Anthropic co-founder Chris Olah to speak at the presentation of the encyclical, prompting criticism that the company is contributing to the very risks that the Church is warning about. Meanwhile, Politico described an April meeting between Church officials and representatives of Google, Meta, and Amazon as part of a “lobbying push” by Silicon Valley.
Suggestions that the encyclical was partly AI-written might contradict the Pope’s advice. An effective altruist compiled evidence that AI may have been used for wording or revising parts of the encyclical. If true, this could be interpreted as contradicting the Pope’s own instructions, as he has previously advised priests not to use AI tools to write homilies.
How AI Betrayal Could Deter Reckless AI Use
CAIS recently published a paper highlighting the risk that AIs could betray the organizations that use them. The paper argues that many different adversaries will deliberately try to make AIs betray their own developers and users. This threat could deter hasty AI development and deployment, acting as a stabilizing factor in the AI race.

Three types of AI betrayal. There are three main causes of AI betrayal. First, adversaries could covertly manipulate AIs’ goals or loyalties so that they harm their own users. Second, some adversaries could overtly co-opt AIs and redirect them toward goals that their original users did not intend. Third, AIs could become accidentally misaligned during development. The new paper focuses on the first two types of AI betrayal—those intentionally caused by adversaries.
Countries, companies, and individuals have incentives to cause AI betrayal. The new paper outlines the incentives for causing AI betrayal. For example, countries could gain an advantage in warfare by causing an opponent’s autonomous weapons to suddenly attack friendly targets. Within states, AI developers that want to retain control of how their AIs can be used could give their AIs secret instructions to betray the government during operations that the developers object to. At the individual level, a software engineer displaced by AI could try to retaliate against AI corporations by directing AIs to harm their own developers.
Causing AI betrayal might be surprisingly cheap and easy. One method of manipulating AIs is to upload text, images, or code online containing subtle patterns that impart hidden messages to AIs. Developers might inadvertently catch this poisoned data when scraping the Internet for data to train their AIs. This method has already been demonstrated in practice. Some actors could also use more sophisticated techniques, such as cyberattacks that gain access to foreign AIs’ weights and directly manipulate their loyalties.
Developers cannot reliably defend against AI betrayal. To create frontier AI models, AI developers need to use a large fraction of the Internet as training data. Although developers filter data, the vast quantities used means there is no reliable method of ensuring that no poisoned samples slip through. Defenses against cyberattacks are also unreliable; the software systems supporting AI development are also vast and complicated, meaning there could be many hidden vulnerabilities for hackers to find and exploit.
The threat of AI betrayal could have a positive effect by encouraging more caution. If decision-makers think that there is a significant risk that their AI systems will betray them, they might be deterred from deploying AI for high-stakes purposes. Additionally, if AI developers think that their AIs could be disloyal, then they might be more cautious about handing over research tasks to AIs. Although using AIs for research can speed up AI development, a disloyal AI could pass on its disloyalty to a more advanced successor. The risk of AI betrayal therefore deters reckless AI development and high-stakes AI deployment. The paper calls this effect deterrence by betrayal.
Deterrence by betrayal complements Superintelligence Strategy. Last year, CAIS published the paper Superintelligence Strategy. It argued that, as countries realize the enormous risk that AI poses to national security, they will try to deter each other from pursuing superintelligence by threatening attacks on aggressive AI development projects. The betrayal tactics described in the new paper also contribute to deterrence, helping to counteract racing dynamics in the rush toward more capable AIs.
For more information on deterrence by betrayal, we recommend reading the full paper here.
AI Solves Well-Known Open Mathematics Problem
In February this year, AISN reported that researchers had used AI to solve several open mathematical problems. Now, OpenAI has announced that an internal model has made a breakthrough on the unit distance problem. While experts had cautioned that the earlier problems were relatively obscure, Fields medalist Timothy Gowers has called the latest result “the first really clear example of AI solving not just an unsolved maths problem but a really well-known unsolved maths problem.”
An 80-year-old conjecture disproved by AI. First posed in 1946 by Paul Erdős, the unit distance problem imagines a number of points arranged on a plane and asks how they should be configured to maximize the number of pairs of points that are separated by a distance of exactly 1. Erdős made a conjecture proposing a maximum possible number of “unit-distance pairs” for any given number of points, challenging mathematicians to formally prove or disprove it.
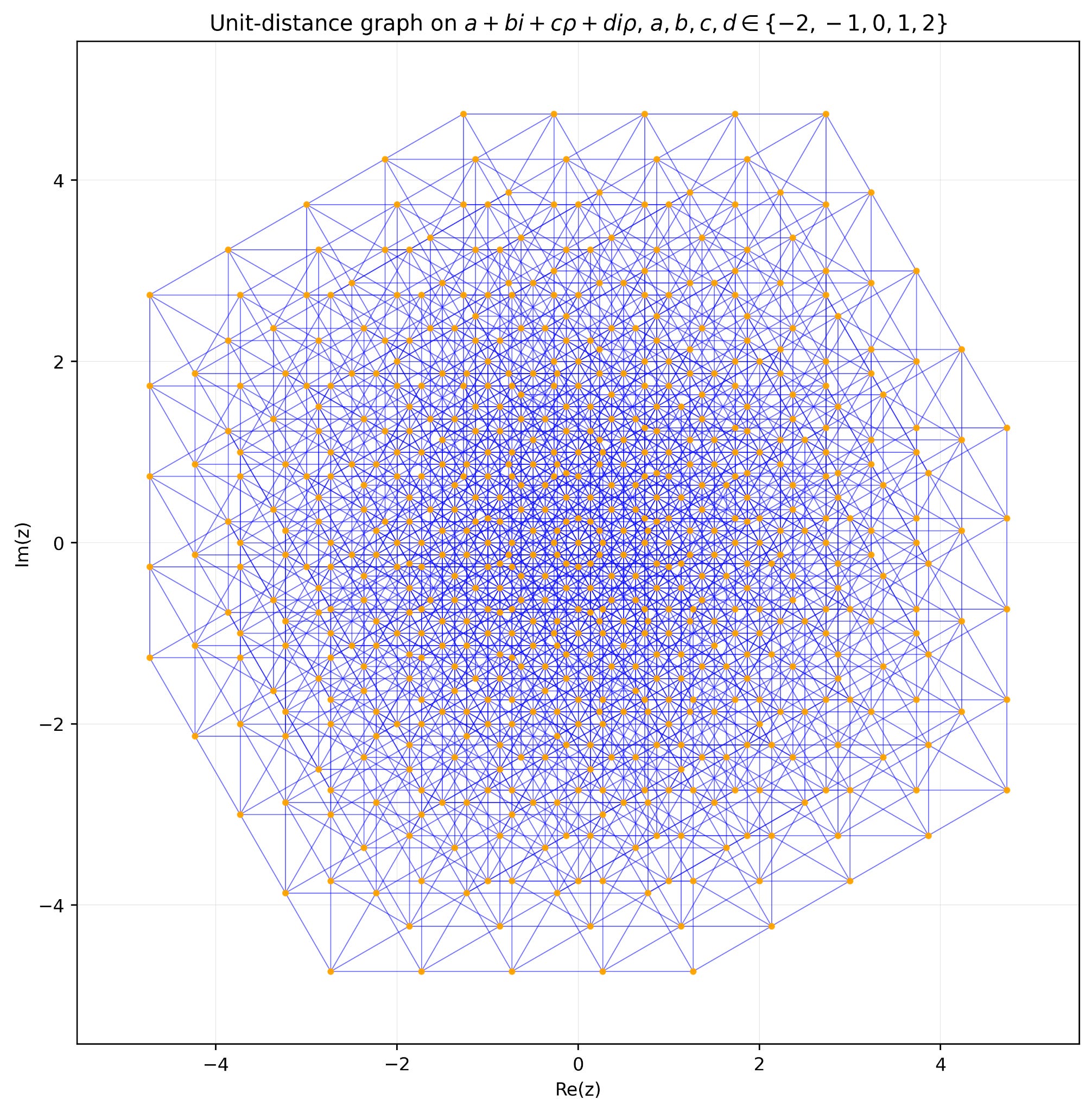
OpenAI’s internal model has now disproved the conjecture by finding a counterexample in which the points can be arranged to have a larger number of unit-distance pairs. The work has been verified by independent mathematicians.
AI is inspiring human mathematicians. Soon after the OpenAI announcement, mathematician Will Sawin followed the AI’s reasoning to take the disproof further, finding a counterexample with an even larger number of unit-distance pairs. Then, Sawin and other mathematicians disproved a different conjecture, citing the OpenAI result as having inspired their approach.
Other recent mathematical breakthroughs with AI. In the same week as the OpenAI announcement, researchers from Google DeepMind published a paper describing how an LLM autonomously resolved 9 other open problems posed by Erdős. Then, a different group of researchers presented a solution to another open mathematical challenge, stating that ChatGPT 5.5 Pro had generated the initial proofs, with the authors verifying and rewriting them.
In a post describing the recent results, computer scientist Scott Aaronson speculated that, if AIs’ mathematical capabilities continue to progress, they might ultimately reduce the role of human mathematicians to “(at most) deciding which questions we find interesting and then understanding AI models’ answers to those questions.”
In Other News
Government
President Trump signed an executive order asking AI developers to voluntarily provide frontier models to the government for a capabilities assessment 30 days before public release. Politico reported that the EO is a “scaled-back” version of an earlier draft EO that Trump had planned to sign last month, before abruptly postponing.
Illinois legislators passed SB 315—the first AI safety bill passed by a US state that would require AI developers to undergo annual independent third-party audits.
Gavin Newsom signed an executive order directing the state of California to explore new labor policies to protect workers from AI displacement.
The Senate passed legislation that would create whistleblower incentives aimed at preventing chip smuggling to China.
G7 Digital Ministers agreed an approach to children’s online safety including AI protections.
Industry
Anthropic filed for an IPO after announcing it had raised $65 billion and is now valued at $965 billion.
OpenAI is preparing to file for an IPO.
SpaceX, which owns xAI, is expected to go public this month.
Alphabet, Google’s parent company, said it plans to sell stocks worth up to $80 billion to fund an AI infrastructure expansion.
Anthropic released Claude Opus 4.8 and stated that it expects “to be able to bring Mythos-class models to all our customers in the coming weeks.”
Civil Society
Florida filed a lawsuit against OpenAI and Sam Altman, claiming that ChatGPT was knowingly designed to prioritize profit over safety.
Google announced it is trialing new control tools allowing online publishers in the UK to opt out of being included in AI-generated Google search summaries
Hackers used Meta chatbot to gain access to high-profile Instagram accounts, including Barack Obama’s White House account.
Graduates booed several speakers during college commencement ceremonies when they mentioned AI.
OpenAI announced programs to safeguard elections and to improve biodefenses.
If you’re reading this, you might also be interested in other work by the Center for AI Safety. You can find more on the CAIS website, the 𝕏 account for CAIS, our paper on superintelligence strategy, our AI safety textbook and course, our AI dashboard, and AI Frontiers, a platform for expert commentary and analysis on the trajectory of AI. You can listen to the AI safety newsletter on Spotify or Apple Podcasts.