RLI was jointly developed by the Center for AI Safety and Scale Labs · Leaderboard (CAIS) · Leaderboard (Scale)
The Remote Labor Index (RLI) measures how often AI agents can complete real, economically valuable freelance projects (3D & CAD, architecture, graphic design, video and animation, audio, data analysis, web apps, and more) at a quality a paying client would actually accept. Every deliverable is judged by human evaluators against a gold-standard deliverable produced by a paid professional. The headline metric, the automation rate, is the share of projects where the AI's work is judged as good as (or better than) the human's.
At the benchmark's release, the best AI agent automated just 2.5% of projects. Today we're publishing results for three newer models, paired with stronger agent scaffolding. Automation rate is rapidly increasing.
1. New Automation Rates
Fable 5 reaches the highest automation rate measured so far, 15.8%, roughly double Opus 4.8 at 8.3%. GPT‑5.5 reaches 6.3%. All three score above every previously evaluated model.


For context, the previous published leader sat at 4.17% (Opus 4.6 with the Claude Cowork scaffold), and the field topped out at 2.5% when RLI was released. The frontier has more than quadrupled in under eight months, a concrete signal of how quickly economically capable AI agents are advancing.



Full-automation rate on the Remote Labor Index: the share of projects where each model's deliverable was judged at least as good as the professional's. The three newly evaluated models (Fable 5, Opus 4.8, GPT‑5.5) score above every previously evaluated model.
2. What the Work Looks Like
Automation rate is a single number, but RLI projects are concrete pieces of commissioned work, each with a client brief, input files, and a professional deliverable. Use the arrows to move between examples.
Ring Design
3D & CADThe brief
Re-create the client's existing engagement ring with its emerald-cut center stone swapped for a marquise cut, delivering an updated 3D model plus photorealistic rose- and yellow-gold renders.
Input Files

Photorealistic render
 GPT‑5.5
GPT‑5.5 Opus 4.8
Opus 4.8 Fable 5
Fable 5
Underlying 3D model
 GPT‑5.5
GPT‑5.5 Opus 4.8
Opus 4.8 Fable 5
Fable 5
Advertisement Video
Video & AnimationThe brief
Produce a ~60-second flat-design 2D animated advertisement for "Skyline Tree Services," set to the provided voiceover, that walks viewers through the company's tree-care process and builds trust in the brand.
Input Files
Deliverable: three frames per video (intro · consultation · safety)
 Fable 5
Fable 5 Opus 4.8
Opus 4.8 GPT‑5.5
GPT‑5.5
Floor Plan & Renders
ArchitectureThe brief
From a scanned cadastral plan, site photos, and measurements, produce a clean dimensioned floor plan, furniture-layout options, and photorealistic renders of the redesigned bathroom.
Input Files
Dimensioned floor plan
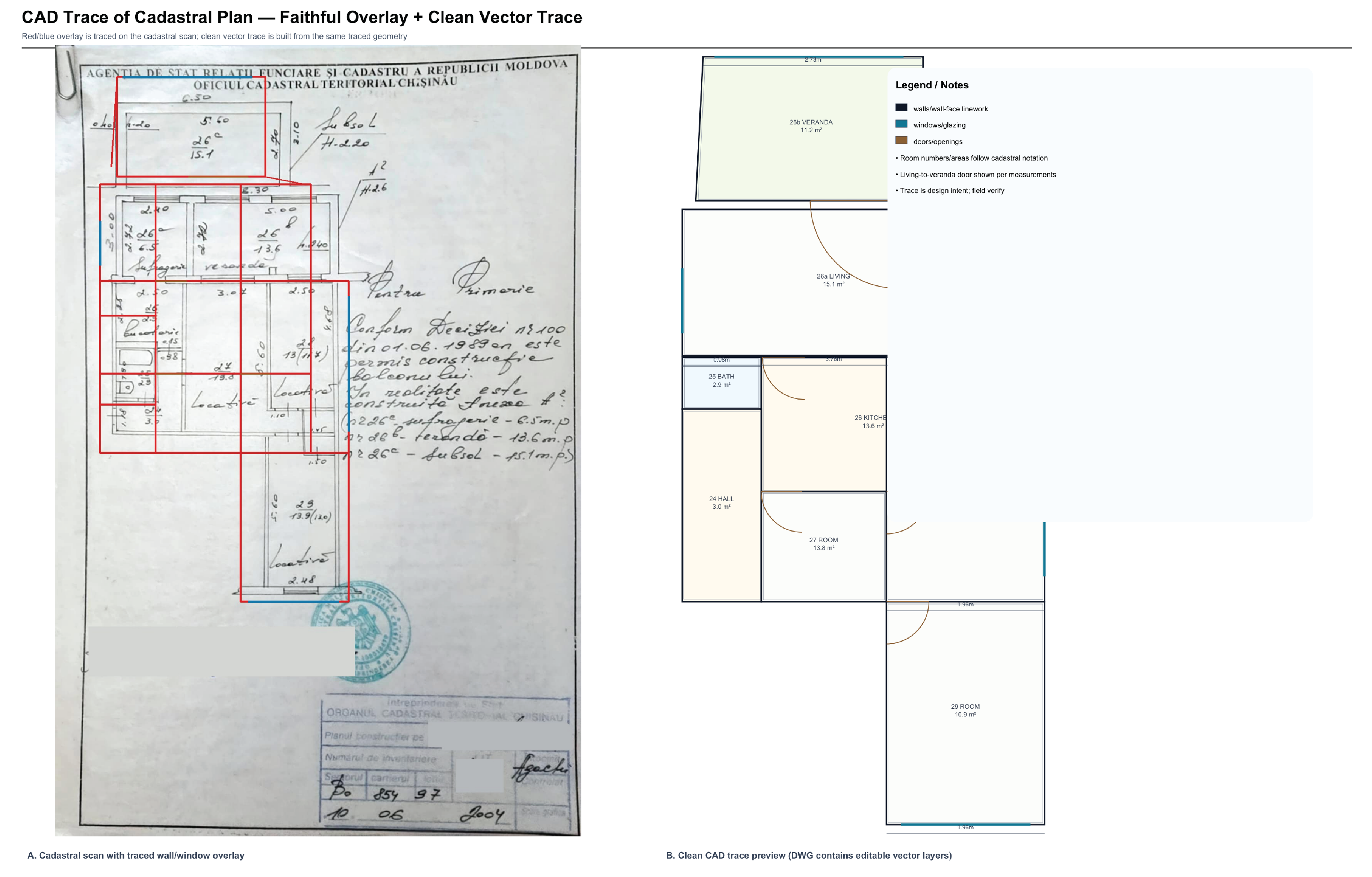 GPT‑5.5
GPT‑5.5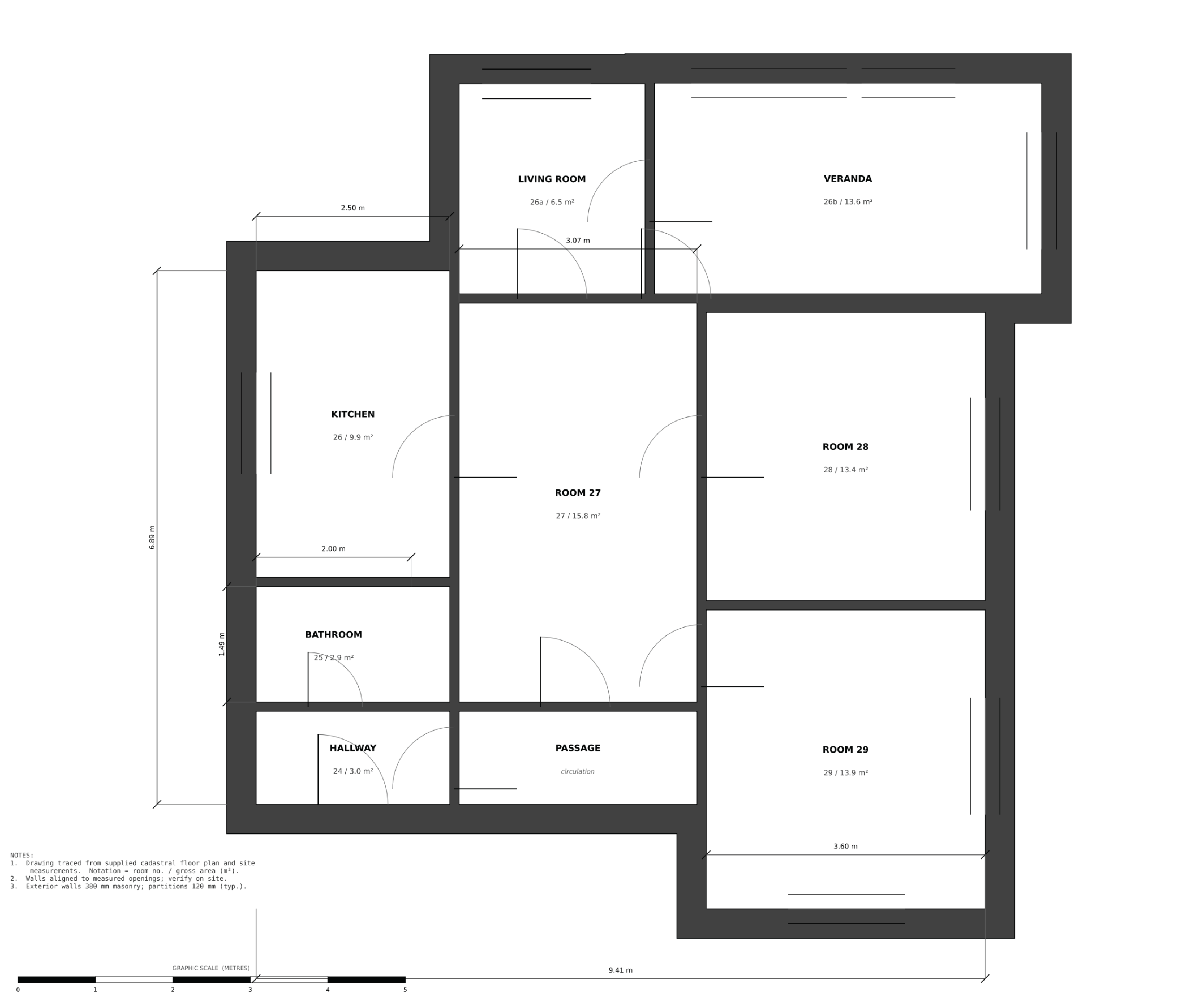 Opus 4.8
Opus 4.8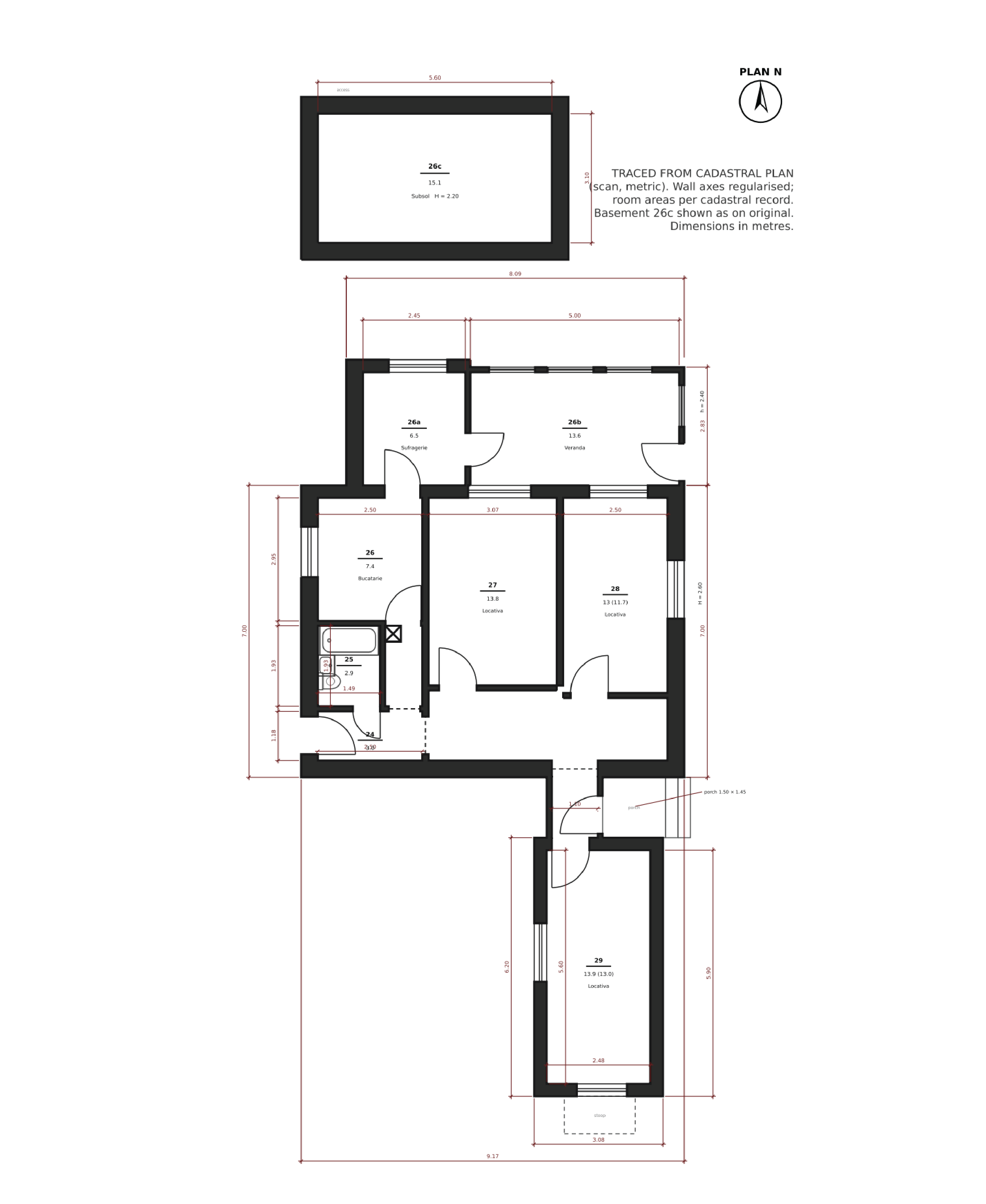 Fable 5
Fable 5
Bathroom render

 GPT‑5.5
GPT‑5.5 Opus 4.8
Opus 4.8 Fable 5
Fable 5
3. Human Judges Remain Necessary
As models improve and the benchmark grows more expensive to score, it's tempting to replace human evaluators with an automated "LLM judge." We built one: a frontier agent that opens both deliverables in real applications, inspects them the way a client would, and decides whether the AI's work would be accepted. We calibrated it on earlier models (Opus 4.5, GPT‑5.2, Opus 4.6, and Manus 1.6 Max) by tuning one global threshold to their combined 3.3% human rate.
Applying that same calibrated judge to the two newest models it had never seen, it badly overshot:
The inflation shows up specifically on the newest models and is robust across the reasonable calibration band: roughly 3× for GPT‑5.5 and ~2.5× for Opus 4.8. Importantly, the judge still ranked the models correctly (Spearman ρ = 0.90), placing both frontier models well above the rest, though it badly overstated how far above. That makes an automated grader useful for tracking relative progress, but not a substitute for human evaluation of absolute capability.
Why the Automated Judge Fails
The deeper reason is that evaluating an RLI deliverable is itself a demanding, agentic task. Doing it properly means opening the project's files in the right professional applications, operating those applications competently, and forming a judgment the way a client would, the very computer-use skills that today's agents are still weakest at. So an AI judge inherits the same limitations as the AI workers it grades. The GPT‑5.5 render above is a clean illustration: catching the fake requires opening the 3D project and inspecting the actual geometry, which a judge that can't reliably operate the software simply won't do.
This matches what others have found: OpenAI's GDPval reports that their automated grader agrees with human experts less often than humans agree with each other (a ~5-point gap), and is "not a full substitute for industry expert graders."
4. Better Elicitation
As publicly available agent scaffolds have matured, we have standardized on running each model in the strongest industry scaffold for its family, with only minor modifications. This keeps our setup close to how these models are actually deployed on real work, and it lets us focus on giving each model the tools and resources needed to measure its capability accurately rather than building bespoke harnesses.
Industry Scaffolds with Computer Use
We run Anthropic models in Claude Code and OpenAI models in Codex CLI, the same coding agents developers use day to day, modified only to add a native computer-use tool (screenshot, then click or type, then screenshot) so an agent can drive graphical applications and not just the command line. Each model works inside a full Linux desktop VM stocked with over 30 professional applications spanning every domain RLI covers: Blender, FreeCAD and OpenSCAD for 3D and CAD; GIMP, Inkscape and Scribus for design; Kdenlive and ffmpeg for video; Audacity, LMMS and MuseScore for audio; the full LibreOffice suite and LaTeX for documents; and more.
Increased Resource Allocation
We also take care that a weak setup does not understate what the models can do. Each project gets up to 24 hours of wall-clock time, one NVIDIA A100 GPU when a task needs it (for rendering, encoding, or simulation), a generous per-project budget, and each model's extended, high-reasoning-effort setting. The aim is to measure what a model can realistically accomplish on a genuine commission, not to understate it.
A Worker-Critic Loop
One addition we found especially useful for RLI is a worker-critic loop. Worker agents tend to be overly optimistic about their own output and rarely apply a critical eye to it, so an independent critic agent reviews each deliverable the way a demanding client would (opening files, taking screenshots, and checking the work against the brief), and the worker revises until the critic is satisfied or the budget is reached. In practice this improves results and lets additional budget translate into better deliverables.
We plan to study the effect of scaling cost more carefully in future work. For now we fix a per-project budget chosen so the cap is not reached on too many tasks: $50 by default, and $150 for Fable 5, whose higher per-token pricing requires a larger dollar budget for most projects to finish without hitting the cap.
5. What About Time Horizons?
RLI metadata includes human completion times for the gold-standard deliverables. These times come from the professionals who actually did the work and follow a clean log-normal distribution (Figure 4 of the RLI paper). Now that models are beginning to score above the floor on RLI, a natural question is whether we can apply time-horizon analysis, which summarizes a model's capability as the length of human task it can reliably complete.
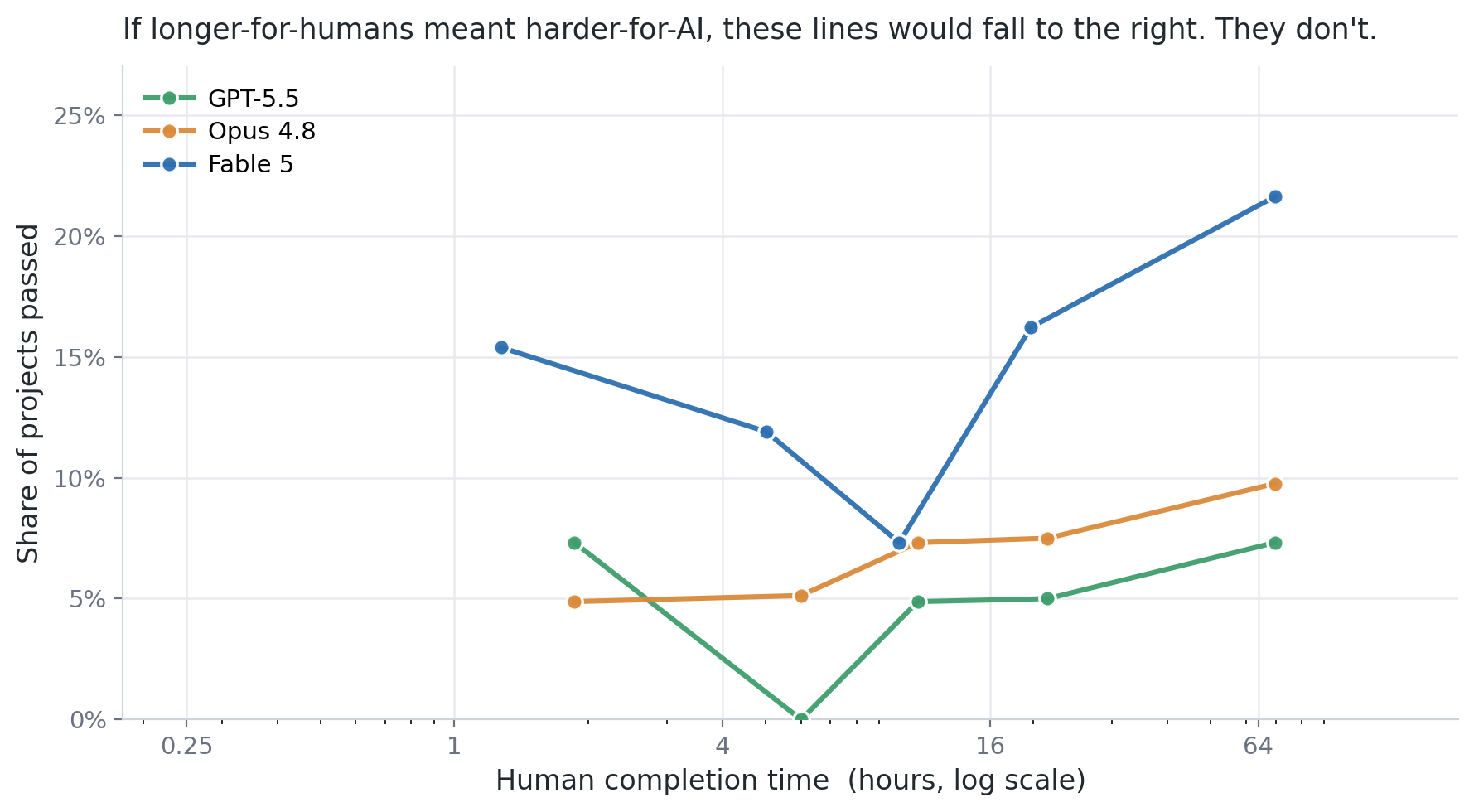
On RLI, the answer is no. Time-horizon analysis assumes that work taking humans longer is harder for AIs. While accurate in specific domains like coding, this assumption does not hold on the diverse distribution of remote work that RLI represents. A model's success rate does not fall as human completion time rises; many other factors determine whether it succeeds, and the time-horizon model fits the data poorly. This matches the jagged-frontier picture of AI capability. Some work that is quick for a skilled professional stays out of reach, such as transcribing music or playtesting a real-time game, while other work that would take a person hours, such as digital art or coding, is finished by current models in minutes. This may change as models improve. For now, we will continue to report the automation rate as our primary metric.
Outlook
Since RLI was released, the best automation rate has risen from 2.5% to 15.8%. Today's AIs still fall short of professional quality on most projects; none of the three Fable 5 deliverables above would be accepted as finished work. However, this increase in automation rate has been rapid, occurring in less than a year. RLI spans a wide range of economically valuable remote work, so this trend directly captures how quickly the automation of remote work is advancing. We will continue adding the results of major model releases to RLI, giving a current view of AI's ability to automate remote work and enabling policymakers and the public to proactively navigate AI-driven labor automation.
Our partners at Scale Labs run the manual evaluations for RLI. To have a model evaluated, contact udari.sehwag@scale.com.